Essas são minhas notas de estudos, elas podem ser atualizadas com o tempo ou não, além de não necessariamente serem organizadas no formato de textos.
Tabela de Conteúdo
- Support Vector Machine (SVM)
- Linear SVM para classificação (SVC)
- Não Linear SVM para classificação
- SVM Regression
- Detectando Outliers
- Resumo
- Referências
Support Vector Machine (SVM)
O modelo SVM é capaz de fazer classificações, regressões e identificar novos dados, sendo possível utilizá-lo para ajustes lineares e não lineares. Este modelo é melhor aplicado em dataset de tamanhos pequenos e médios, e escala bem com o número de features, principalmente se forem esparsas.
Linear SVM para classificação (SVC)
A ideia por trás do algoritmo de SVC é definir uma linha que separa as classes, mas com a condição extra dessa linha estar o mais distante possível das duas classes. A imagem abaixo mostra um exemplo do resultado final do SVC, onde a linha do meio (traço em vermelho) é a linha que separa as classes e as linhas laterais (pontilhadas em preto) são os vetores de suporte, são esses vetores que o algoritmo tenta afastar o máximo possível da linha do meio.
![]()
Imagem por Larhmam - Own work, CC BY-SA 4.0, Link
O algoritmo de SVM só pode ser utilizado para classificar duas classes, é um classificador binário. Porém, existem formas de se contornar essa limitação.
O modelo SVM é sensível a escala das features, sendo necessário colocá-las na mesma escala. Além disso, o modelo SVC (SVM linear) também regulariza o termo de bias (constante), sendo necessário centralizar os valores das features.
Para controlar a regularização, utilizamos o hiperparâmetro $C$. Para valores baixos de $C$, permitimos que alguns pontos entrem dentro das margens pontilhadas, chamamos esse efeito de margens suaves (soft margin). Para um valor alto de $C$, não aceitamos pontos dentro das margens pontilhadas, esse efeito é chamado de margem dura (hard margin). Quando o modelo apresenta overfitting, podemos reduzir o valor de $C$ para aplicar uma regularização.
O modelo de SVM não retorna de forma direta as probabilidades para cada classe. Porém existem formas de se obtê-las.
Não Linear SVM para classificação
O modelo de SVM também consegue fazer classificações não lineares. Isso é feito por meio do truque do kernel. A ideia é análoga a de criar features não lineares a partir de features lineares, como por exemplo ao fazermos uma transformação polinômil da feature linear $X$ para $X^n$, onde $n$ é um valor inteiro. Esse tipo de transformação pode facilitar a classificação tornado uma região de separação não linear, como uma circular, em uma região de separação linear, como uma linha, a figura abaixo mostra um exemplo desse tipo de transformação.
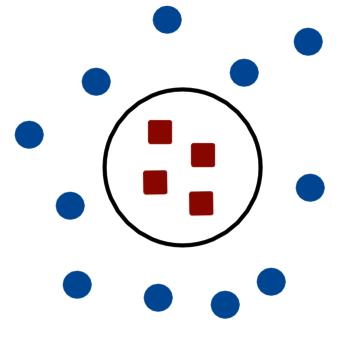

SVM Kernel
Apesar do truque de transformar features lineares em não lineares funcionar, adicionar várias features não lineares aumenta muito o tamanho do dataset. Por isso o modelo de SVM usa o truque do kernel, no qual as transformações das features são feitas de forma indireta, por meio da escolha do kernel a ser utilizado. Com isso, obtemos resultados semelhantes a uma transformação não linear das features, porém sem o onus de adicionarmos novas features ao dataset. Os kerneis mais comumente utilizados são o polinômial e o RBF guassiano (Radial Basis Function).
Ao utilizarmo o kernel polinômial de grau $n$, é como se o modelo estivesse transformando as features $X$ e $Y$ em combinações $X^2$, $Y^2$, $XY$ e etc, antes de fazer o fit. Obviamente, se o modelo apresentar overfit, é só uma questão de reduzir o grau do kernel polinômial utilizado.
O kerenl RFB guassiano é equivalente a transformamos as features usando uma função guassiana que mede similaridade entre os pontos do dataset. A largura da guassiana considerada no kernel é controlado por meio do hiperparâmetro $\gamma$, valores baixos aumentam a largura da guassiana enquanto valores altos diminuem a largura. Se o modelo apresentar overfit é só diminuir o $\gamma$, isso vai relaxar as restrições do uso de uma guassiana muito centrada.
SVM Regression
A ideia é inverter o que o algoritmo de SVM fazia na classificação, invés de tentar separar os pontos, tentamos colocar o máximo de pontos dentro das linhas pontilhas como mostrado na primeira imagem. A distância da linha pontilhada é controlada pelo hiperparâmetro $\epsilon$.
Detectando Outliers
SVM podem ser usados para detectar outliers, porém o algoritmo não tem um desempenho muito bom nesta tarefa. Ele é melhor utilizado para detectar dados novos quando o dataset não possui outliers, como é descrito na documentação do Scikit-Learn.
Resumo
-
O algoritmo de SVM só pode ser utilizado para classificar duas classes, é um classificador binário. Porém, existem formas de se contornar essa limitação.
-
O modelo de SVM não retorna de forma direta as probabilidades para cada classe. Porém, existem formas de se obtê-las.
-
O modelo SVM é sensível a escala das features, sendo necessário colocá-las na mesma escala. Além disso, o modelo SVC (SVM linear) também regulariza o termo de bias (constante), sendo necessário centralizar os valores das features.
-
Não funciona bem se as classes estiverem sobrepostas.
-
Eficaz em casos onde o número de features é maior que o número de amostras.
Referências
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow - Livro