Essas são minhas notas de estudos, elas podem ser atualizadas com o tempo ou não, além de não necessariamente serem organizadas no formato de textos.
Tabela de Conteúdo
- Voting Classifiers (hard and soft)
- Bagging e Pasting
- Avaliação Out-of-Bag
- Random Patches e Random Subspaces
- Boosting
- AdaBoost
- Gradient Boosting
- Stacking
- Referências
Voting Classifiers (hard and soft)
Uma forma de melhorar o resultado de uma classificação é combinar os resultados de diversos classificadores. Existem dois jeitos de fazer isso, o primeiro é utilizar como resultado a classe mais votada entre todos os classificadores considerados, isso é chamado de voto duro (hard voting). A segunda opção é utilizarmos a média das probabilidades, obtidas de cada classificador, e escolhermos como resultado final a classe com a maior probabilidade, esse método é chamado de voto suave (soft voting), e gera melhores resultados. Porém, o voto suave tem a restrição do classificador retornar uma probabilidade e não uma classificação.
O método de ensemble funciona melhor quando temos diversos classificadores independentes, isto é, cada modelo vai errar e acertar fazendo considerações diferentes. Desta forma, toda vez que um classificador fizer uma previsão errada é esperado que outro classificador encubra esse erro, e no final obtemos sempre uma previsão melhorada.
As previsões são melhores, mas não são muito melhores. Não é surpresa ver uma previsão melhorar somente em $0.2\%$.
Bagging e Pasting
Para obter uma previsão mais precisa, não temos necessariamente que utilizar diversos modelos. Podemos separar o dataset de treino de forma aleatória em diversos pedaços, treinar o mesmo modelo em cada um desses pedaços e agregar os resultados usando o voto duro ou suave, por exemplo.
Nesta abordagem, cada um dos modelos possui um viés (bias) maior. Porém, ao agregarmos os resutlados diminuímos tanto o viés quanto a variância. Normalmente os resultados vão gerar um modelo com um viés similar, mas com uma variância menor.
Duas possíveis formas para dividir o dataset são o Bagging e o Pasting. Em ambos os métodos, as instâncias de treino são escolhidas de forma aleatória, porém somente no Bagging podemos escolher mais de uma vez a mesma instância de treino. Sendo possível vermos a mesma instância repetida diversas vezes na mesma divisão do dataset.
O método de Bagging gera uma diversidade maior nos novos dataset, com isso temos um viés maior do que o seria encontrado no Pasting. Porém, a diversidade extra diminui a correlação, fazendo com que a variância seja menor. De forma geral, Bagging é mais utilizado reduzir a variância.
Avaliação Out-of-Bag
Outra vantagem do Bagging é que algumas instâncias de treino nunca são utilizadas. Como a escolha é aleatória e a mesma instância pode ser escolhida mais de uma vez, algumas instâncias simplesmente não são escolhidas. Sendo assim, as instâncias que não foram escolhidas podem ser consideradas como um dataset de validação, onde o modelo pode ser avaliado. Esta validação é chamada de out-of-bag (oob). Em cada um dos obb, usamos o respectivo modelo treinado e avaliamos suas previsões, a média do erro gerado nessas previsões é uma estimativa do desempenho do modelo em um dataset desconhecido.
Random Patches e Random Subspaces
A classe de Bagging, especificamente do Scikit-Learn, suporta também a amostragem de features. A ideia é a mesma, dividimos aleatoriamente as features em pedaços, treinamos o modelo e em seguida avaliamos os resultados exatamente como foi feito com as instâncias. Chamamos de Random Patches quando amostramos tanto as instâncias de treino quanto as features, e de Random Subspaces quando amostramos somente as features. A vantagem de escolher aleatoriamente as featues é de aumentar a diversidade do ensemble, o que diminui a variância do modelo. Outra vantagem é que não precisamos treinar o modelo utilizando todas as features, isso pode ser uma vantagem em dataset com uma grande quantidade de features.
Boosting
Boosting é um método de Ensemle que combina diversos modelos fracos para gerar um modelo mais forte, que faz previsões melhores. A ideia é treinar em sequência esses modelos, isto é, o resultado do primeiro modelo serve de entrada para o segundo modelo. Desta forma cada modelo corrige os erros do seu predecessor.
AdaBoost
O AdaBoost dá mais peso para as instâncias de treino mais difíceis. Por exemplo, as instâncias que foram classificadas erradas pelo primeiro modelo recebem um peso maior e são repassadas como entradas para o próximo modelo. Desta forma, à medida que utilizamos mais e mais modelos, o AdaBoost consegue agrupar os modelos fracos e gerar um modelo mais forte.
Se o Adaboost estivar dando overfitting, podemos reduzir a quantidade de modelos, considerar modelos mais fortes ou adicionar alguma regularização aos modelos.
Gradient Boosting
Gradient Boosting utiliza a mesma ideia base do AdaBoost, combinar modelos fracos em sequência para gerar um estimador melhor. A diferença está em como corrigimos os erros dos modelos fracos. A ideia é adicionar diversos modelos em sequência, onde cada um corrige o erro apresentado pelo modelo anterior. De forma mais explicita, o que é feito é: obtemos os resultados do primeiro modelo, calculamos o seu erro residual e depois usamos esse resíduo como entrada para o próximo modelo. Desta forma, a cada modelo adicionado em sequência, corrigimos um pouco do erro obtido pelo modelo primeiro modelo, obtemos assim um modelo melhor a partir de diversos modelos mais fracos.
De forma mais técnica, os modelos posteriores ao primeiro modelo estão ajustando uma curva aos erros residuais do modelo anterior, estão “aprendendo” uma função que descreva esse erro. A previsão final é obtida ao somarmos os resultados de cada um dos modelos, i.e., previsão do primeiro + correção dos erros.
Novamente, o uso de muitos modelos vai causar overfitting. No Scikit-Learn o hiperparâmetro learning_rate escala a contribuição de cada modelo, geralmente uma árvaro de decisão, sendo que valores baixos reduzem as chances de overfitting.
Stacking
Stacking tem como base a ideia de usar um modelo, como uma rede neural, para agregar os valores obtidos por diferentes modelos. Anteriormente, discutimos a opção de agregar os resultados usando o voto duro ou suave, apesar de ser um método válido não essas são funções triviais e podem não gerar os melhores resultados.
A forma como fazemos isso segue a seguinte ordem:
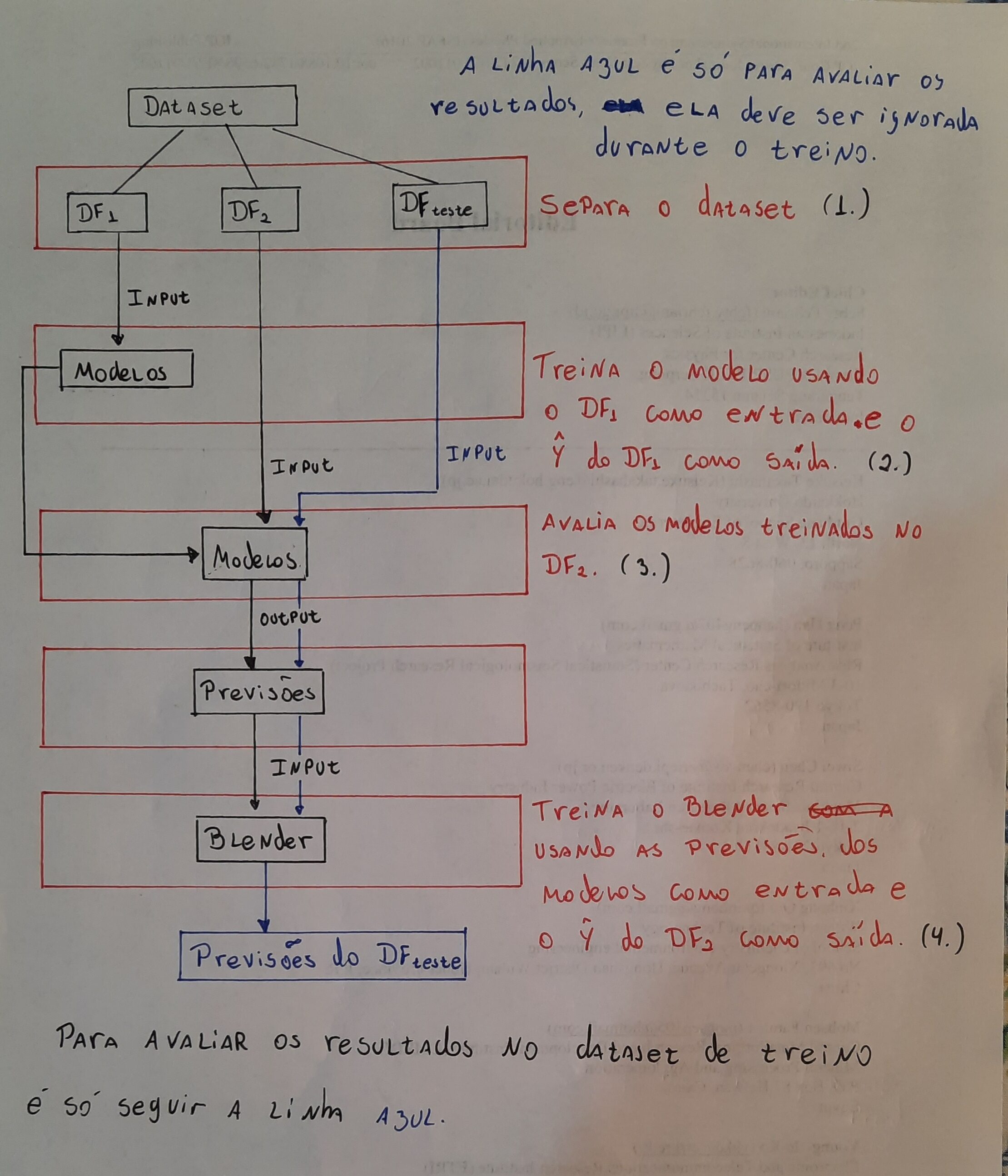
- Separe o dataset em duas partes, $\text{df}_1$ e $\text{df}_2$.
- Treine um ensemble de modelos, $\text{models}_1$, usando $\text{df}_1$.
- Faça previsões usando $\text{models}_1$ no dataset $\text{df}_2$, vamos chamar o ensemble de previsões geradas de $\text{pred}_1$.
- Treine outro modelo, como uma rede neural ou um regressor linear, usando como entrada o $\text{pred}_1$ e como resultado esperado o $\hat{y}$ do $\text{df}_2$. Esse modelo é chamado de blender, é ele que vai repesar os resultados obtidos pelos outros modelos, $\text{pred}_1$, e gerar previsões melhores.
A imagem abaixo reproduz o processo de treino.
Existe a possibilidade de adicionar mais uma camada de modelos, porém o dataset tem que ser dividido em $3$ partes. Nas referências tem um livro onde isso é explicado.
Referências
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow - Livro