Essas são minhas notas de estudos, elas podem ser atualizadas com o tempo ou não, além de não necessariamente serem organizadas no formato de textos.
Tabela de Conteúdo
- Revisão de conceitos
- Curva ROC
- A curva ROC padrão
- O problema do desbalanço de classes
- Curva PR
- Resumo
- Referências
Revisão de conceitos
Matriz Confusão
Existem $4$ possíveis resultados gerados por um modelo de classificação binária (classe $0$ ou classe $1$):
-
Verdadeiros positivos (TP): positivos classificados corretamente (classe $1$).
-
Verdadeiros negativos (TN): negativos classificados corretamente (classe $0$).
-
Falsos positivos (FP): Classe negativa que é classificada como positiva pelo modelo.
-
Falsos negativos (FN): Classe positiva que é classificada como negativa pelo modelo.
Considerando estas $4$ saídas, montamos a matriz confusão onde temos as previsões do modelo $Ŷ(x)$ para a classe $x$ e as previsões corretas para as classes $0$ e $1$, dada por,
| 1 | 0 | Soma das linhas | |
|---|---|---|---|
| Ŷ(1) | TruePositives (TP) | FalsePositives (FP) | Ŷ1 = TP + FP |
| Ŷ(0) | FalseNegatives (FN) | TrueNegatives (TN) | Ŷ0 = FN + TN |
| Soma das colunas | P = TP + FN | N = FP + TN |
onde N é o número total de exemplos negativos, P é o número total de exemplos positivos, Ŷ0 é o número total de exemplos negativos previsto pelo modelo e Ŷ1 é o número total de exemplos positivos previsto pelo modelo.
Outras métricas
Outras métricas também utilizadas com base nos possíveis resultados do modelo binário são:
- Accuracy:
-
Do conjunto de todos os pontos, qual a porcentagem de acertos do modelo. $$Acc = \frac{TP + TN}{P+N}$$
- Precision:
-
Do conjunto dos positivos verdadeiros, qual a porcentagem de positivos verdadeiros classificados corretamente pelo modelo. $$Pr = \frac{TP}{Ŷ1}$$
- Sensitivity, Recall, $TP_{rate}$:
-
Do conjunto de todos os positivos previstos pelos modelo, qual a porcentagem de positivos verdadeiros classificados corretamente pelo modelo. $$ Rc = \frac{TP}{P}$$
- Specificity:
-
Do conjunto de todos os negativos previstos pelos modelo, qual a porcentagem de negativos verdadeiros classificados corretamente pelo modelo. $$Sp = \frac{TN}{N}$$
- $F_1$ score:
-
Essa métrica combina precision e recall em um métrica única. $F_1$ é chamada de média harmônica entre precision e recall, sendo mais indicada para comparar dois modelos. Além disso, note que valores baixos de precision e recall geram uma $F_1$ pequena, o contrário também é verdadeiro. $$F_1 = \frac{2}{1/\text{Pr} + 1/\text{Rc}} = \frac{Tp}{Tp + \frac{FN+FP}{2}}$$
Curva ROC
A curva ROC é dada pelo gráfico da taxa de falsos positivos ($TP_{rate}$) pela taxa de verdadeiros positivos ($FP_{rate}$). Neste gráfico, representamos cada modelo como um ponto. Sendo que, o modelo ideal fica próximo ao ponto $(0,1)$, i.e., baixa taxa de falsos positivos e alta taxa de verdadeiros positivos. Enquanto o ponto oposto, $(1,0)$, representa o pior modelo possível, pois nunca consegue prever nenhum verdadeiro positivo. Entre estes pontos, temos a linha $TP_{rate}=FP_{rate}$, modelos próximos a esta linha obtêm resultados aleatórios, se acertam $70\%$ dos pontos verdadeiros positivos, também indicam $70\%$ dos pontos como falsos positivos.
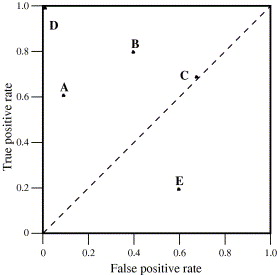 Ponto D é o modelo ideal, pontos A e B são bons, ponto C é um modelo aleatório
e ponto E é um modelo muito ruim.
Ponto D é o modelo ideal, pontos A e B são bons, ponto C é um modelo aleatório
e ponto E é um modelo muito ruim.
De forma mais explicita, queremos modelos mais distantes da linha que divide o gráfico e mais próximos do ponto $(0,1)$.
Uma forma mais minuciosa de interpretar os modelos é dada pela proximidade com os pontos $(0,0)$ e $(1,1)$.
-
Modelo Conservativo $(0,0)$: Um modelo conservador só classifica pontos como positivos se tiver muita certeza. Desta forma, o modelo tem uma taxa baixa de falsos positivos, mas também tem uma taxa baixa de verdadeiros positivos. Podem ser modelos aceitáveis quando o custo de se cometer um erro é muito alto.
-
Modelo Liberal $(1,1)$: Um modelo mais liberal, classifica muitos pontos como positivos, mesmo com baixas evidências. Consequentemente, o modelo tem uma taxa alta de verdadeiros positivos, mas também possui uma taxa alta de falsos positivos. Podem ser modelos aceitáveis quando as consequências de errar não são graves.
A curva ROC padrão
Até aqui, falamos sobre um único ponto no plano ROC gerado por um modelo. Porém, podemos construir uma curva inteira usando os resultados de um único modelo. Para gerar essa curva, precisamos que o modelo tenha como saída uma distribuição de probabilidade continua, $(0,1]$, e não uma classificação binária, $0$ ou $1$.
Alguns modelos como o Random Forest, só retornam classificações binárias, não sendo possível obter a curva ROC inteira a partir de um modelo, conseguiríamos somente um único ponto. Porém, existem outras formas de se contornar este tipo de problema, fazendo com que o modelo de Random Tree retorne uma classificação semelhante a uma probabilidade, mas este tópico não será abordado aqui.
Para gerar a curva ROC, considere que entramos com $x$ exemplos no modelo e obtemos as probabilidades $Ŷ(x)$ de $x$ pertencer a classe $0$ ou a classe $1$. Agora, defina um valor de corte $C$ e classifique as classes como:
-
$0$: Se $Ŷ(x) < C$
-
$1$: Se $Ŷ(x) > C$
Desta forma, para cada valor de $C$ escolhido teremos valores diferentes de $TP_{rate}$ e $FP_{rate}$, gerando assim um ponto no plano ROC para cada valor de $C$. Ao variarmos $C$ entre $(0,1]$ de forma continua, conseguimos obter a curva ROC inteira. Além disso, este procedimento nos permite escolher valores de $C$ para o qual o modelo está mais próximo do ponto ideal $(0,1)$.
O problema do desbalanço de classes
As curvas ROC não são sensíveis a mudanças na distribuição de classes do problema, como pode ver nos gráficos abaixo. Essa propriedade é fácil de ser entendida, já que cada um dos eixos do gráfico ($TP_{rate}$ e $FP_{rate}$) dependem somente de uma única classe, $TP_{rate}$ só depende do número de classes positivas e $FP_{rate}$ só depende do número de classes negativas. Em contraste, métricas como accuracy, precision e F-score, usam valores das duas colunas da matriz confusão, e por isso não sensíveis a mudanças na distribuição de classes. O valor dessas métricas mudam ao mudarmos a distribuição de classes mesmo que a performance do modelo não mude.
De fato, a curva ROC não é sensível a mudanças na distribuição de classes. Porém, isso nem sempre é algo bom. Curvas ROC não são boas para avaliar problemas que possuem naturalmente classes desbalanceadas. Para entender o problema, considere um modelo que tem como ponto no plano ROC $TP_{rate} = 0.8$ e $FP_{rate} = 0.2$. Ao aplicarmos este modelo em dois dataset, um balanceado com $1.000$ exemplos da classe $1$ e $1.000$ exemplos da classe $0$, e outro desbalanceado com $500$ exemplos da classe $1$ e $2.000$ exemplos da classe $0$. Obtemos os seguintes resultados, para o dataset balanceado o modelo classifica $800$ ($1.000 * 0.8$) exemplos como verdadeiros positivos e somente $200$ ($1.000 * 0.2$) como falsos positivos. Um excelente modelo. Porém, ao aplicarmos ao dataset desbalanceado o modelo classifica $400$ ($500 * 0.8$) exemplos como verdadeiros positivos e $400$ ($2.000 * 0.2$) como falsos positivos. O mesmo modelo, com o mesmo ponto na curva ROC, não é considerado um bom modelo quando as classes estão desbalanceadas, pois encontra falsos positivos e verdadeiros positivos na mesma proporção. Desta forma, não podemos usar a curva ROC para avaliar modelos que tenham dataset naturalmente desbalanceados como em segmentação de imagens e análise de risco. Uma forma melhor de avaliar dataset desbalanceados é utilizando o gráfico PR (Precision Recall).
Curva PR
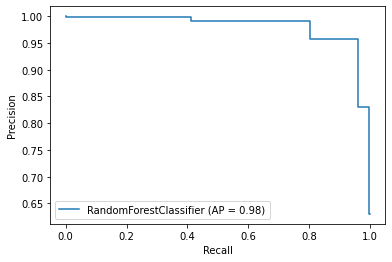
A curva PR é dada pelo gráfico de precison por recall. O modelo ideal fica próximo ao ponto $(1,1)$, onde temos uma taxa baixa de falsos positivos e uma taxa baixa de falsos negativos. A linha que define um modelo que prevê classes de forma aleatória é uma linha reta proporcional a quantidade de exemplos positivos utilizados. Um exemplo de curva PR está na imagem abaixo.
Resumo
Você deve usar a curva PR quando a classe positiva ($1$) é rara ou quando os falsos positivos são mais importantes que os falsos negativos. Se este não for o caso, a curva ROC pode ser usada.
O objetivo da curva ROC (Receiver Operating Characteristic) é resumir de forma simples e visual a performance do modelo em uma classificação binária. Suas características são:
-
Não é sensível a mudanças nas proporções de classes, i.e., conseguimos a mesma curva ROC se o dataset de teste estiver com as classes desbalanceadas.
-
Não é bom para avaliar modelos onde as classes são naturalmente desbalanceadas, como acontece em segmentação de imagens e análise de risco.
-
Modelos com pontos próximos ao ponto $(0,1)$ são modelos ideais. O contrário é válido para o ponto $(1,0)$.
-
Modelos com pontos na linha $y=x$ estão escolhendo os resultados de forma aleatória.
-
O valor ideal da ROC AUC é de $1$.
O objetivo da curva PR (Precision Recall) é resumir de forma simples e visual a performance do modelo em uma classificação binária. Suas características são:
-
Diferente da curva ROC, a curva PR é sensível a mudança na distribuição de classes.
-
É boa para avaliar modelos onde as classes são naturalmente desbalanceadas, como acontece em segmentação de imagens e análise de risco.
-
Modelos com pontos próximos ao ponto $(1,1)$ são modelos ideais. O contrário é válido para o ponto $(0,0)$.
-
Modelos com pontos na linha que é proporcional ao número de resultados positivos, são modelos que escolhem os resultados de forma aleatória.
-
O valor ideal da PR AUC é de $1$.
Referências
An introduction to ROC analysis - Artigo
Receiver Operating Characteristic (ROC) - scikit-learn
ROC Curves and Precision-Recall Curves for Imbalanced Classification - Machine Learning Mastery