Tabela de Conteúdo
- A ideia do algoritmo
- Como o algoritmo decide as divisões
- Usando a Decision Tree para obter probabilidades
- Regularização
- Regressão
- Instabilidade
- Referências
A ideia do algoritmo
Decision Tree, ou árvore de decisão, é um algoritmo versátil que pode ser usado tanto para classificação quanto para regressão, sendo capaz de encontrar padrões em datasets muito complexos. Além disso, Decision Trees são os componentes fundamentais do algoritmo de Random Forest.
O algoritmo de Decision Tree necessita de pouco ou nenhum pré-pocessamento de dados, não sendo necessário reescalá-los ou centralizá-los. Esse é um dos motivos pelo qual ele é muito utilizado. Além disso, a árvore de decisão é considerada um modelo white box, pois gera resultados fáceis de serem interpretados, ao contrário dos algoritmos de Neural Networks e Random Forest que possuem uma interpretação mais complicada, estes modelos são chamados de black box.
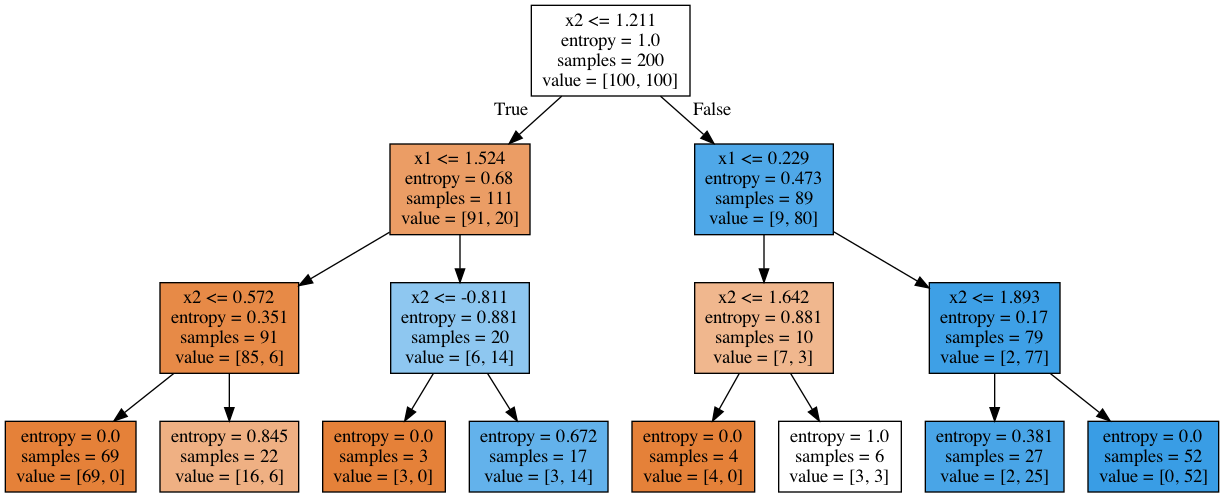
Considerando um caso de classificação, o algoritmo de árvore de decisão cria um fluxograma que descreve o processo de tomada de decisão para separar as classes, como na figura abaixo. Desta forma, conseguimos facilmente entender o que o algoritmo levou em consideração na tomada de decisão. Note que a tomada de decisão é feita por meio de perguntas de verdadeiro ou falso, mas também podem aparecer testes numéricos como $X_a < 1.5$ dependendo do tipo de variável que foi utilizada.
 |
|---|
| Imagem por Yury Kashnitsky - CC BY-SA 4.0,site. |
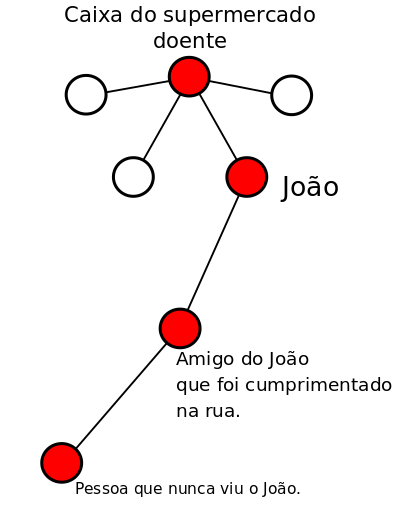
Para entender melhor como o algoritmo separa as classes, vamos definir alguns nomes. Chamaremos de nó cada um dos blocos do fluxograma, o nó zero (primeiro bloco) é chamado de nó raiz e os nós que não possuem ramificações, i.e., os nós finais de onde obtemos as previsões das classes, são chamados de folhas. A alusão a uma árvore é facilmente compreendida, a árvore cresce a partir da raiz (nó zero), gerando ramificações até atingir uma folha, de onde a árvore não cresce mais.
Interpretando cada parâmetro do algoritmo
- Samples: É a quantidade de instâncias de treino onde o nó pode ser aplicado.
- Value: Considerando o número de amostras (Samples), o Value conta quantas amostras pertencemm a cada classe.
- Entropy: Mede o valor da entropia em cada nó. Um valor baixo é melhor para fazer previsões.
Como o algoritmo decide as divisões
A divisão é feita com o intuito de minimizar a entropia de cada nó. Entropia é um conceito originado da termodinâmica, onde seu objetivo inicial era o de medir a desordem ou o “caos” do sistema. Porém, ele também pode ser interpretado como a quantidade de informação que temos sobre um sistema. Por exemplo, em um sistema com baixa entropia, ou uma desordem menor, podemos fazer previsões de forma mais fácil, enquanto em um sistema com alta entropia, que apresenta grande desordem (caos), fica mais difícil de fazer qualquer previsão. Então, a ideia do algoritmo é fazer perguntas que diminuam a entropia a cada nó, até que consigamos fazer previsões precisas sobre o sistema.
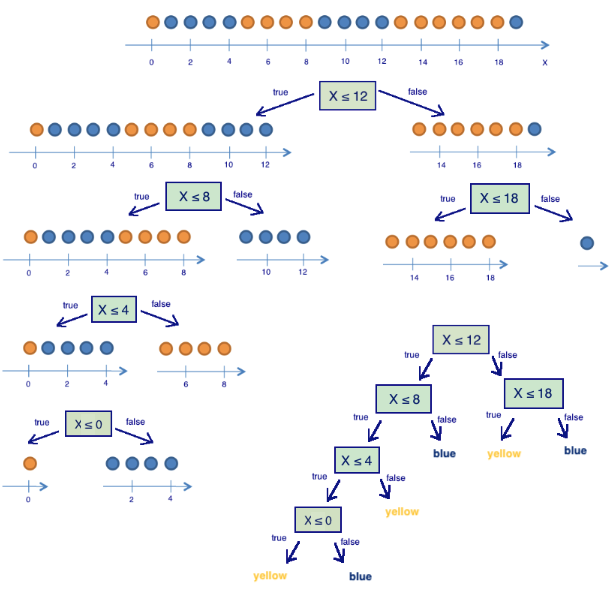
Um bom exemplo de como o algoritmo toma decisão, com os cálculos da entropia, é encontrado neste site, aqui nós só vamos reproduzir a imagem. Considere o conjunto de bolinhas de cores amarela e azul abaixo, o objetivo é criar uma árvore de decisão que separe as bolinhas em dois grupos com cores únicas. Note que cada pergunta criada, baseada na posição da bolinha, diminui a entropia de forma que ao final consigamos separar claramente os dois grupos.
 |
|---|
| Imagem por Yury Kashnitsky - CC BY-SA 4.0,site. |
O pacote do Scikit-Learn usa o algoritmo de CART para separar os nós. Este algoritmo só é capaz de produzir duas ramificações em cada nó, ou seja, uma separação binária de sim ou não. Essa é só uma limitação do algoritmo utilizado, existem outro algoritmos capazes de produzir mais do que duas ramificações por nó.
Usando a Decision Tree para obter probabilidades
O algoritmo de Decision Tree pode retornar a probabilidade de uma instância de treino pertencer ao uma classe. Após o treino, dado uma instância (amostra) do dataset, o algoritmo segue o fluxograma criado pela árvore de decisão até encontrar uma folha que classifique a instância usada. Após encontrar a folha, o algoritmo calcula a fração Value/Samples, ou seja, divide a quantidade de instâncias da classe prevista pela folha para aquela instância, pelo número total de instâncias que chegaram até a folha. Dessa forma, definimos a “probabilidade” da instância escolhida pertencer a uma certa classe. Note que esta probabilidade é fixa, a mesma instância sempre vai gerar a mesma probabilidade, sem nenhum tipo de flutuação.
Regularização
É comum observamos overfit ao usarmos árvores de decisão. Como não definimos um limite para o crescimento da árvore, o algoritmo pode dividir o dataset da forma que ele quiser e em quantas partes ele quiser. Desta forma, se deixarmos o algoritmo se adaptar, sem nenhuma restrição aplicada previamente, ele muito provavelmente vai atingir o overfit do dataset de treino.
Modelos que não precisão da escolha prévia de hiperparâmetros são chamados de modelos não paramétricos.
Algoritmos paramétricos, como a regressão linear e outros, possuem um número predefinido e limitado de parâmetros, o que reduz o grau de liberdade para fazer o ajuste. Isso limita as chances de algoritmos paramétricos atingirem o overfit, eles apresentam muito mais underfit do que overfit.
A regularização do modelo para prevenir o overfit é feita controlando alguns hiperparâmetros, como a profundidade da árvore (max_depth), o número máximo de features consideradas (max_features), o número minímo de amostras (Samples) para que o algoritmo possa criar novos ramos a partir de um nó (min_samples_split e min_samples_leaf).
A documentação do Scikit-Learn apresenta duas dicas importantes ao usarmos o algoritmo de Decision Tree. Primeiro, devemos considerar o uso de algoritmos de redução de dimensionalidade como PCA e ICA. Segundo, devemos entrar com os dados como tipo np.float32, se usarmos np.float64 (padrão do Python) o algoritmo vai fazer uma cópia dos dados e consumir mais memória.
Regressão
A árvore de decisão também consegue fazer regressões, o valor retornado pela folha é a média dos valores obtidos por cada uma das instâncias daquela folha. Se criassemos um gráfico com os dados e regressão obtida do algoritmo, iríamos ver que a regressão é feita por linhas retas com valores constantes, o valor dessa constante é exatamente a média dos valores obtidos por cada instâncias em uma das folhas.
Instabilidade
A árvore de decisão tem a tendência de separar as classes usando linhas perpendiculares e ortogonais a algum eixo das features, isso gera divisões em regiões retangulares. Isso gera problemas se o dataset puder ser separado por uma linha reta com uma inclinação de $45^{\circ}$. Neste caso, apesar do algoritmo conseguir separar as classes do dataset, as bordas das regiões serão muito mais complexas do que uma simples linha reta, a divisão vai parecer com diversos degraus. Isso também nos mostra que a árvore de decisão é muito sensível a alterações no dataset, até mesmo as simples. Imagine um dataset que foi separado pela árvore de decisão por uma linha vertical, se rotacionarmos o dataset em $45^{\circ}$ o algoritmo não mais utilizaria uma linha reta para separar o dataset, seria necessário uma função muito mais complexa.
Referências
Hands-On Machine Learning with Scikit-Learn, Keras, and TensorFlow - Livro
]]>

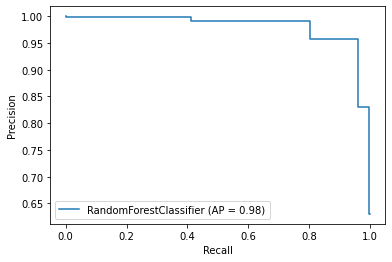
 Ponto D é o modelo ideal, pontos A e B são bons, ponto C é um modelo aleatório
e ponto E é um modelo muito ruim.
Ponto D é o modelo ideal, pontos A e B são bons, ponto C é um modelo aleatório
e ponto E é um modelo muito ruim.